DeepSeek代碼開源第二彈:DeepEP通信庫,優(yōu)化GPU通信快訊
DeepSeek今日向公眾開源了DeepEP——第一個用于MoE模型訓練和推理的開源EP通信庫,DeepEP是一個用于MoE(混合專家)模型訓練和推理的EP(Expert Parallelism)通信庫,它為所有GPU內(nèi)核提供高吞吐量和低延遲。
【TechWeb】2月25日消息,繼昨天開源Flash MLA后,DeepSeek今日向公眾開源了DeepEP——第一個用于MoE模型訓練和推理的開源EP通信庫。

據(jù)介紹,DeepEP是一個用于MoE(混合專家)模型訓練和推理的EP(Expert Parallelism)通信庫,它為所有GPU內(nèi)核提供高吞吐量和低延遲,也稱為MoE調(diào)度和組合。該庫還支持低精度操作,包括FP8。
同時,DeepEP針對NVLink(NVLink是英偉達開發(fā)的高速互聯(lián)技術(shù),主要用于GPU之間的通信,提升帶寬和降低延遲)到RDMA(遠程直接內(nèi)存訪問,一種網(wǎng)絡(luò)數(shù)據(jù)傳輸技術(shù)?,用于跨節(jié)點高效通信)的非對稱帶寬轉(zhuǎn)發(fā)場景進行了深度優(yōu)化,不僅提供了高吞吐量,還支持SM(Streaming Multiprocessors)數(shù)量控制,兼顧訓練和推理任務(wù)的高吞吐量表現(xiàn)。
對于對延遲敏感的推理解碼,DeepEP包含一組低延遲內(nèi)核和純RDMA,以最大限度地減少延遲。該庫還引入了一種基于鉤子的通信計算重疊方法,該方法不占用任何SM資源。
DeepSeek稱,DeepEP的實現(xiàn)可能與DeepSeek-V3論文略有不同。
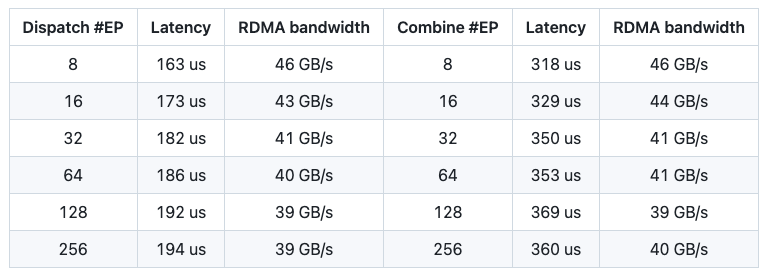
DeepSeek還列出了DeepEP的實際性能:
在H800(NVLink的最大帶寬約為160 GB/s)上測試常規(guī)內(nèi)核,每臺設(shè)備都連接到一塊CX7 InfiniBand 400 Gb/s的RDMA網(wǎng)卡(最大帶寬約為50 GB/s),并且遵循DeepSeek-V3/R1預訓練設(shè)置(每批次4096個Tokens,7168個隱藏層單元,前4個組,前8個專家(模型),使用FP8格式進行調(diào)度,使用BF16格式進行合并)。

在H800上測試低延遲內(nèi)核,每臺H800都連接到一塊CX7 InfiniBand 400 Gb/s的RDMA網(wǎng)卡(最大帶寬約為50 GB/s),遵循DeepSeek-V3/R1的典型生產(chǎn)環(huán)境設(shè)置(每批次128個Tokens,7168個隱藏層單元,前8個專家(模型),采用FP8格式進行調(diào)度,采用BF16格式進行合并)。
DeepEP運行環(huán)境要求:
Hopper GPU(以后可能支持更多架構(gòu)或設(shè)備)
Python 3.8及以上版本
CUDA 12.3及以上
PyTorch 2.1及以上版本
NVLink用于內(nèi)部節(jié)點通信
用于節(jié)點間通信的RDMA網(wǎng)絡(luò)
1.TMT觀察網(wǎng)遵循行業(yè)規(guī)范,任何轉(zhuǎn)載的稿件都會明確標注作者和來源;
2.TMT觀察網(wǎng)的原創(chuàng)文章,請轉(zhuǎn)載時務(wù)必注明文章作者和"來源:TMT觀察網(wǎng)",不尊重原創(chuàng)的行為TMT觀察網(wǎng)或?qū)⒆肪控熑危?br>
3.作者投稿可能會經(jīng)TMT觀察網(wǎng)編輯修改或補充。
