僅用40張圖片就能訓練視覺模型:CVPR 2019伯克利新論文說了什么?互聯網+
導讀
伯克利大學研究小組提出的Open Long-Tailed Recognition (OLTR) 開放長尾識別,為計算機視
伯克利大學研究小組提出的Open Long-Tailed Recognition (OLTR) 開放長尾識別,為計算機視覺系統在現實世界中的應用提供了新的分類標準。
在工業界的熱情參與下,AI行業大會近年來的發展可謂是如火如荼。不過,依然很少有哪個能比得上CVPR在計算機視覺領域的影響力。其中, 又以oral口頭報道的文章最具重量級。
那么在CVPR 2019中,又有哪些成果獲此殊榮呢?
伯克利大學研究小組提出的Open Long-Tailed Recognition (OLTR) 開放長尾識別,就為計算機視覺系統在現實世界中的應用提供了新的分類標準。
 以往的CV系統存在哪些問題,OLTR又提供了哪些解決方案?不妨通過一篇文章搶先了解一下。
以往的CV系統存在哪些問題,OLTR又提供了哪些解決方案?不妨通過一篇文章搶先了解一下。
實驗室與現實的距離: 神經網絡的“視覺盲點”
長久以來,我們理解中的機器視覺往往是這樣工作的:
研究人員會依據圖像所具有的本身特征先將其分類,然后設計一個算法,使用設定好的數據集進行預訓練。然后,給AI一張圖片,它會根據存儲記憶中已經分好的類別進行識別,查看是否有與該圖像具有相同或類似特征的存儲記憶,從而快速識別出是該圖像。只要投喂足夠多的照片,特征分類足夠準確,識別算法的精準度也會逐步提升。
模式識別技術近兩年突飛猛進,加上在公共安全、工業、農業、交通、生物等領域的不斷落地,比如車牌識別、人臉識別、指紋識別、心電圖檢測等等,是應用最為成熟、群眾基礎最為廣泛的AI技術之一。
但,問題也出在這里。
由于訓練數據和測試數據都是在封閉環境下進行的,比如ImageNet數據集,這與現實世界中的情況卻截然不同。
因為在現實中,充斥著許多無法出現在測試數據集中的開放類別。它們要么數量珍貴而稀少,比如自然界中的野生動物;要么繁多而不規律,諸如街道標志、時尚品牌、面孔、天氣狀況、街道狀況等等,在日常生活分布的概率也是不平衡的。
如果只是簡單地將現有的計算機視覺分類放在現實中的識別問題上,結果會怎樣呢?伯克利的研究人員告訴你,就是被打臉。 (現有的計算機視覺分類與現實世界的場景之間存在相當大的差距)
當以為生態學家想利用現有的CV技術來識別相機中所捕捉到的野生動物時,不出意外地,由于沒有足夠的訓練數據,系統失敗了……
(現有的計算機視覺分類與現實世界的場景之間存在相當大的差距)
當以為生態學家想利用現有的CV技術來識別相機中所捕捉到的野生動物時,不出意外地,由于沒有足夠的訓練數據,系統失敗了……
更令人悲傷的是,在此類情境中,收集更多數據是非常不現實的。
對于一些瀕臨滅絕的野生珍稀動物,人們往往要花很長的時間,甚至要等上好幾年才能成功拍到一次照片。與此同時,新的動物物種不斷出現,舊的動物物種不斷離開。在自然界這個動態系統中,識別對象的總分類數從來沒有固定過。
即使現有的計算機視覺技術在大眾類別上做得再好,比如精準識別出人類和貓狗等,但對于這些不均衡的分類對象,現在的方法依然無能為力。
 之所以出現這種問題,核心原因或在于:面對實際應用時,機器視覺的分類任務不應該被作為單項任務來對待并解決,而應該當成一個整體來看待。即一個能夠對少數擁有海量ImageNet數據集的常見類別,以及大多數罕見類別,都能夠進行分類的實用系統。
之所以出現這種問題,核心原因或在于:面對實際應用時,機器視覺的分類任務不應該被作為單項任務來對待并解決,而應該當成一個整體來看待。即一個能夠對少數擁有海量ImageNet數據集的常見類別,以及大多數罕見類別,都能夠進行分類的實用系統。
要實現這一點,就要求CV系統具備一種能力,能夠從幾個已知的事例中推導出單一類別的概念,并對一個從未見過的類別的實際圖例對應上新的概念。這就不再是邏輯命題,而是智慧型的學習命題了。為了盡可能地消滅“次元壁”中存在的“視覺盲點”,OLTR開放長尾識別框架應運而生。
OLTR,讓CV系統更全能
如上所述,“開放長尾識別”(OLTR)的核心任務目標,就是讓系統能夠從長尾數據和開放的分布式數據中進行學習,能夠在包括頭、尾和開放類的平衡測試集上表現出較好的分類精度。
也就是說,除了一些主流的樣本豐富的對象,對于數據匱乏的、分布廣泛導致出現頻率不均衡的物體,系統也能夠做到很好的識別。
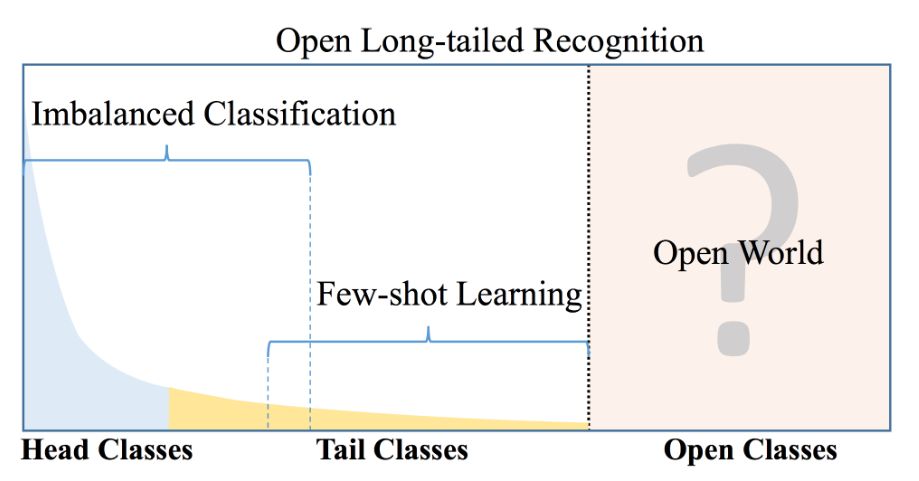 顯然,有了OLTR的機器視覺會變得能力更全面,也更符合現實環境的需求。它的特殊之處,主要依靠視覺記憶能力來實現。
顯然,有了OLTR的機器視覺會變得能力更全面,也更符合現實環境的需求。它的特殊之處,主要依靠視覺記憶能力來實現。
研究人員將圖像映射到一個特征空間,將圖像特征和記憶特征結合在一起,這樣視覺系統就可以基于封閉環境分類的學習度量,對開放世界中存在的新穎物體和長尾類進行理解。即使在缺乏觀察數據和特征的情況下,視覺記憶也能夠對開放類進行理解并努力識別。
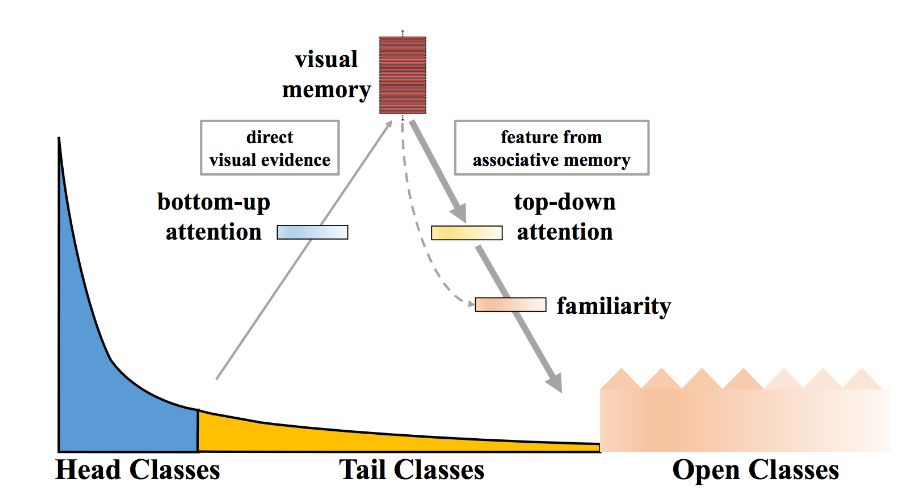 (讓CV系統具備視覺記憶能力)
(讓CV系統具備視覺記憶能力)
實驗結果顯示,記憶特征的加入,使得CV系統能夠更好地激活起視覺神經元。比如,識別“公雞”這一長尾類物體(位于下圖左上角cock)時,具有記憶功能的CV系統已經學會了將其轉換為“鳥頭”、“圓型”和“虛線紋理”的視覺概念,并將被普通CV模型錯誤分類的圖片正確地識別了出來。

 (從內存特性中注入視覺記憶特征的系統示例)
(從內存特性中注入視覺記憶特征的系統示例)
在現實任務中,這種新方法也表現出了極強的開放性,能夠在不犧牲豐富類的前提下,對稀缺類別的識別實現明顯的改進。
以前面提到的認識野生動物為例,對于那些圖像不超過40幅的種類,OLTR實現了從25%到66%的性能提升。
與目前大多數計算機視覺方案相比,OLTR顯然更符合數據自然分布的真實世界。那么,它的出現最有可能給哪些CV技術帶來改變呢?
檢測、分割:CV問題的新解法
可以明確的是,OLTR的出現,解決了CV領域最為經典的問題之一——分類(classification)。那么,自然也就間接影響了分類問題的諸多應用領域。其中,比較多的就是目標檢測和圖像分割。
先說說目標檢測。
目標檢測已經在諸多產業中都有應用,簡單的論文也越來越難發表了,比如手機拍照中用一個框來定位人臉,或者是智能監控中的人體定位,都屬于目標檢測的范疇。
但關于它的技術探索還遠沒有達到勸退科學家的程度,這是因為,目標檢測算法目前還存在著不少亟待突破的難點:
比如數據標注的巨大成本,能不能通過更有小弟分類來解決;小規模數據的監督學習怎樣才能更有效地提升精度;對單圖像單類別場景進行弱監督多類檢測學習等等。
這些都是應用場景中比較需要關注的問題,恰好也是OLTR能夠帶來改變的地方。
 再說圖像分割。簡單來說就說輸入一張圖片,然后對每一個像素點都進行分類標記,則完成了對整個圖片的分割。
再說圖像分割。簡單來說就說輸入一張圖片,然后對每一個像素點都進行分類標記,則完成了對整個圖片的分割。
比如深度學習對醫學影像進行解讀和診斷,自動駕駛汽車區分人、車、障礙物等,就采用了語義分割的技術。
但該類算法目前面臨著三大難題:一是計算成本高,要保證準確率,需要的存儲空間和數據都非常龐大。二是計算效率低,由于需要對每個像素塊進行計算卷積,造成了很大程度的重復和算力浪費;三是性能桎梏,受像素塊的限制,感知神經元往往只能提取一些局部特征,從而影響分類識別的準確率。
節約計算量、盡可能考慮全局信息、高性能分類,是圖像分割未來迭代的重點。
 此時,OLTR的優勢就展現出來了。
此時,OLTR的優勢就展現出來了。
首先,它用增強視覺記憶的方式,幫助CV系統在頭部類別的基礎上完成尾部、開放類別的特征分類與學習,這意味著可以告別超大規模的數據集,通過小樣本的無監督學習一樣能夠達到同樣的高精度性能,降低了計算機視覺的應用和訓練成本。
其次,由于OLTR具有通用化、整體性的分類能力,使得CV系統能夠在現實環境中表現的更好,尤其是面對一些出現頻率低、難以進行監督訓練的物體時,系統能夠根據以往的“經驗”為其賦予新的視覺概念并識別出來。對于性能要求極高的自動駕駛、醫療診斷等應用來說,無疑是雪中送炭。
總而言之,OLTR的出現,將給CV算法、軟件與產業應用都帶來不小的改變。但其勢能有多大,還需要有越來越多的開發者和企業開始嘗試用其解決現實問題,逐步迭代升級,后續想必還會有不少驚喜。
即使是習以為常的技術,也有自我思考和蝶變的可能。身處時代變革中心的我們,不妨共同期待一下CPVR 2019還有哪些創造。
那么在CVPR 2019中,又有哪些成果獲此殊榮呢?
伯克利大學研究小組提出的Open Long-Tailed Recognition (OLTR) 開放長尾識別,就為計算機視覺系統在現實世界中的應用提供了新的分類標準。
以往的CV系統存在哪些問題,OLTR又提供了哪些解決方案?不妨通過一篇文章搶先了解一下。
實驗室與現實的距離: 神經網絡的“視覺盲點”
長久以來,我們理解中的機器視覺往往是這樣工作的:
研究人員會依據圖像所具有的本身特征先將其分類,然后設計一個算法,使用設定好的數據集進行預訓練。然后,給AI一張圖片,它會根據存儲記憶中已經分好的類別進行識別,查看是否有與該圖像具有相同或類似特征的存儲記憶,從而快速識別出是該圖像。只要投喂足夠多的照片,特征分類足夠準確,識別算法的精準度也會逐步提升。
模式識別技術近兩年突飛猛進,加上在公共安全、工業、農業、交通、生物等領域的不斷落地,比如車牌識別、人臉識別、指紋識別、心電圖檢測等等,是應用最為成熟、群眾基礎最為廣泛的AI技術之一。
但,問題也出在這里。
由于訓練數據和測試數據都是在封閉環境下進行的,比如ImageNet數據集,這與現實世界中的情況卻截然不同。
因為在現實中,充斥著許多無法出現在測試數據集中的開放類別。它們要么數量珍貴而稀少,比如自然界中的野生動物;要么繁多而不規律,諸如街道標志、時尚品牌、面孔、天氣狀況、街道狀況等等,在日常生活分布的概率也是不平衡的。
如果只是簡單地將現有的計算機視覺分類放在現實中的識別問題上,結果會怎樣呢?伯克利的研究人員告訴你,就是被打臉。
(現有的計算機視覺分類與現實世界的場景之間存在相當大的差距)
當以為生態學家想利用現有的CV技術來識別相機中所捕捉到的野生動物時,不出意外地,由于沒有足夠的訓練數據,系統失敗了……
更令人悲傷的是,在此類情境中,收集更多數據是非常不現實的。
對于一些瀕臨滅絕的野生珍稀動物,人們往往要花很長的時間,甚至要等上好幾年才能成功拍到一次照片。與此同時,新的動物物種不斷出現,舊的動物物種不斷離開。在自然界這個動態系統中,識別對象的總分類數從來沒有固定過。
即使現有的計算機視覺技術在大眾類別上做得再好,比如精準識別出人類和貓狗等,但對于這些不均衡的分類對象,現在的方法依然無能為力。
之所以出現這種問題,核心原因或在于:面對實際應用時,機器視覺的分類任務不應該被作為單項任務來對待并解決,而應該當成一個整體來看待。即一個能夠對少數擁有海量ImageNet數據集的常見類別,以及大多數罕見類別,都能夠進行分類的實用系統。
要實現這一點,就要求CV系統具備一種能力,能夠從幾個已知的事例中推導出單一類別的概念,并對一個從未見過的類別的實際圖例對應上新的概念。這就不再是邏輯命題,而是智慧型的學習命題了。為了盡可能地消滅“次元壁”中存在的“視覺盲點”,OLTR開放長尾識別框架應運而生。
OLTR,讓CV系統更全能
如上所述,“開放長尾識別”(OLTR)的核心任務目標,就是讓系統能夠從長尾數據和開放的分布式數據中進行學習,能夠在包括頭、尾和開放類的平衡測試集上表現出較好的分類精度。
也就是說,除了一些主流的樣本豐富的對象,對于數據匱乏的、分布廣泛導致出現頻率不均衡的物體,系統也能夠做到很好的識別。
顯然,有了OLTR的機器視覺會變得能力更全面,也更符合現實環境的需求。它的特殊之處,主要依靠視覺記憶能力來實現。
研究人員將圖像映射到一個特征空間,將圖像特征和記憶特征結合在一起,這樣視覺系統就可以基于封閉環境分類的學習度量,對開放世界中存在的新穎物體和長尾類進行理解。即使在缺乏觀察數據和特征的情況下,視覺記憶也能夠對開放類進行理解并努力識別。
(讓CV系統具備視覺記憶能力)
實驗結果顯示,記憶特征的加入,使得CV系統能夠更好地激活起視覺神經元。比如,識別“公雞”這一長尾類物體(位于下圖左上角cock)時,具有記憶功能的CV系統已經學會了將其轉換為“鳥頭”、“圓型”和“虛線紋理”的視覺概念,并將被普通CV模型錯誤分類的圖片正確地識別了出來。
(從內存特性中注入視覺記憶特征的系統示例)
在現實任務中,這種新方法也表現出了極強的開放性,能夠在不犧牲豐富類的前提下,對稀缺類別的識別實現明顯的改進。
以前面提到的認識野生動物為例,對于那些圖像不超過40幅的種類,OLTR實現了從25%到66%的性能提升。
與目前大多數計算機視覺方案相比,OLTR顯然更符合數據自然分布的真實世界。那么,它的出現最有可能給哪些CV技術帶來改變呢?
檢測、分割:CV問題的新解法
可以明確的是,OLTR的出現,解決了CV領域最為經典的問題之一——分類(classification)。那么,自然也就間接影響了分類問題的諸多應用領域。其中,比較多的就是目標檢測和圖像分割。
先說說目標檢測。
目標檢測已經在諸多產業中都有應用,簡單的論文也越來越難發表了,比如手機拍照中用一個框來定位人臉,或者是智能監控中的人體定位,都屬于目標檢測的范疇。
但關于它的技術探索還遠沒有達到勸退科學家的程度,這是因為,目標檢測算法目前還存在著不少亟待突破的難點:
比如數據標注的巨大成本,能不能通過更有小弟分類來解決;小規模數據的監督學習怎樣才能更有效地提升精度;對單圖像單類別場景進行弱監督多類檢測學習等等。
這些都是應用場景中比較需要關注的問題,恰好也是OLTR能夠帶來改變的地方。
再說圖像分割。簡單來說就說輸入一張圖片,然后對每一個像素點都進行分類標記,則完成了對整個圖片的分割。
比如深度學習對醫學影像進行解讀和診斷,自動駕駛汽車區分人、車、障礙物等,就采用了語義分割的技術。
但該類算法目前面臨著三大難題:一是計算成本高,要保證準確率,需要的存儲空間和數據都非常龐大。二是計算效率低,由于需要對每個像素塊進行計算卷積,造成了很大程度的重復和算力浪費;三是性能桎梏,受像素塊的限制,感知神經元往往只能提取一些局部特征,從而影響分類識別的準確率。
節約計算量、盡可能考慮全局信息、高性能分類,是圖像分割未來迭代的重點。
此時,OLTR的優勢就展現出來了。
首先,它用增強視覺記憶的方式,幫助CV系統在頭部類別的基礎上完成尾部、開放類別的特征分類與學習,這意味著可以告別超大規模的數據集,通過小樣本的無監督學習一樣能夠達到同樣的高精度性能,降低了計算機視覺的應用和訓練成本。
其次,由于OLTR具有通用化、整體性的分類能力,使得CV系統能夠在現實環境中表現的更好,尤其是面對一些出現頻率低、難以進行監督訓練的物體時,系統能夠根據以往的“經驗”為其賦予新的視覺概念并識別出來。對于性能要求極高的自動駕駛、醫療診斷等應用來說,無疑是雪中送炭。
總而言之,OLTR的出現,將給CV算法、軟件與產業應用都帶來不小的改變。但其勢能有多大,還需要有越來越多的開發者和企業開始嘗試用其解決現實問題,逐步迭代升級,后續想必還會有不少驚喜。
即使是習以為常的技術,也有自我思考和蝶變的可能。身處時代變革中心的我們,不妨共同期待一下CPVR 2019還有哪些創造。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
