智譜沒跟上OpenAI觀點
“中國版OpenAI”智譜,意外被OpenAI點了次名。

“中國版OpenAI”智譜,意外被OpenAI點了次名。
近期,OpenAI在一份官方分析師報告中提到,“一家名為智譜AI的初創公司取得了顯著進展,該公司正在多國市場提供一些被稱之為中國版OpenAI for countries 的產品。”圍繞主權AI競爭,OpenAI認為智譜已經成為自己的重要對手之一。
但從當下智譜的實際發展節奏來看,OpenAI的上述報告多少帶了些未雨綢繆的意味。作為曾經全面對標OpenAI的國內大模型玩家,如今的智譜正顯現出越來越跟不上OpenAI的跡象。
持續到來的高管震蕩風波,則進一步影響著智譜自身節奏的變化。
最新離開的是智譜COO張帆。近期,36氪《職場Bonus》爆料稱,張帆將于6月底離職創業。字母榜(ID:wujicaijing)從智譜官方確認了該消息的真實性。據了解,張帆離開后的創業項目也將成為智譜MaaS平臺生態的一份子,且其新項目已獲得智譜的投資支持。
在《無人再談AI六小龍》一文中,字母榜曾率先提出,隨著部分大模型玩家掉隊,當前的六小龍(智譜、MiniMax、月之暗面、階躍星辰、百川智能、零一萬物),已經在事實上縮減為四小強(智譜、MiniMax、月之暗面、階躍星辰)。
而在僅存的AI四小強中,置身這波高管離職潮中的智譜,成了核心高管變動最為頻繁的大模型創業公司之一。
COO張帆之外,《智能涌現》曾報道負責融資的智譜首席戰略官張闊,已于今年1月底離職。更早之前,智譜AI院負責人東昱曉被傳出去年年底離職消息,后得到官方辟謠,稱其本人還在公司名單內。
ChatGPT上線并引領國內大模型創業熱潮后,智譜CEO張鵬對外頻繁講起的一個故事版本是,作為2019年就成立的國內最早研發大模型的創業公司,OpenAI的兩個重要產品發布時刻,對智譜產生了關鍵影響:
一是2020年5月GPT-3的發布,直接將預訓練模型的參數規模推到1000億以上,給了智譜堅持投入大模型訓練的信心;
二是2022年11月ChatGPT的發布,給了智譜一個明顯信號:預訓練模型已經到了完全可使用且好用的階段,是產品化的很好范例。
隨著2024年1月GLM-4模型的發布,智譜一度成為彼時國內唯一一個對標OpenAI全模型產品線的公司:AGI技術路線圖上,對標OpenAI,智譜也規劃了L1-L5的演進路線;基座大模型上,對標GPT-4,智譜推出了GLM-4;文生圖模型上,對標DALL·E 3,智譜上線了CogView3;AI助手上,對標ChatGPT,智譜上架了智譜清言;視頻生成產品上,對標Sora,智譜亮相了智譜清影。
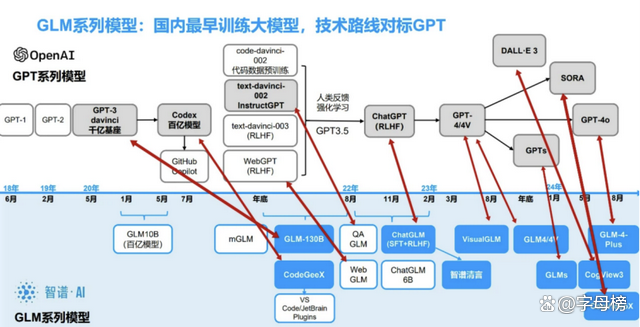
不止于此,在智能體生態構建上,智譜也跟進OpenAI的 GPTs策略,在國內搞了GLMs個性化智能體定制能力。同時,智譜還學習OpenAI,一手研究,一手投資,最早成立了生態基金“Z基金”等等。
但進入2025年,智譜的節奏卻慢了下來。
當OpenAI繼續更迭模型和新產品,繼續將ChatGPT往超級消費型APP方向打造,并展現出押注新一代AI硬件的宏大布局之際,緊跟OpenAI的智譜,不僅在模型更新速度上慢了下來,在產品新功能上新和商業化推進上,也落在了后面。
在談及后發者優勢時,張鵬曾將其概括為兩件事,“一個是技術本身的更新迭代,一個是技術到產品的PMF(產品市場匹配度)”。
年初DeepSeek R1的爆火,便是對技術更新迭代之下的后發者優勢的一次極致體現。
如今,將訓練下一代基座模型視為最高優先戰略的智譜,如何像DeepSeek一樣,也將技術更新迭代的后發優勢再度展現給外界呢?
A
2024年1月自研模型GLM-4發布之前,智譜幾乎保持了每三到四個月便完成一次基礎模型迭代的更新節奏:2023年6月,GLM-2發布;2023年10月,GLM-3發布,這被張鵬視為正常的研發速度。
但在去年底推出對標o1的推理模型后,智譜的大模型更新節奏便慢了下來,2025年的模型更新還都是基于GLM-4版本來做進一步的優化。
反觀OpenAI,在去年推出基礎模型GPT-4和推理模型o1后,進入2025年,奧特曼幾乎以每周都有新產品的更新頻率,讓OpenAI牢牢定在了AI熱搜榜上:基礎模型側,推出了GPT-4.5、GPT-4.1;推理模型側,上線了o3-mini/o4、o3-Pro。
大模型更新緩慢的現實,直接影響著C端用戶的規模增長。2023年10月,智譜清言上線之際,ChatGPT月活已經突破1億用戶。截至今年3月份,ChatGPT月活被曝已經增長至6億,智譜清言則不足500萬。
直觀的數字對比之外,在引領用戶功能體驗方面,智譜也落后OpenAI一大截。盡管同樣都有文生圖模型能力加持,但OpenAI憑借GPT-4o,在3月份一力主導了吉卜力風格圖片的流行,智譜的GLM-4V多模態,卻未能創造出相對應的亮眼表現。
值得一提的是,OpenAI還在有意拉大跟同行的競爭差距。在智譜們還在追趕模型性能之際,OpenAI切切實實準備大搞AI硬件了。5月份,OpenAI斥資65億美元收購了io,一家由前蘋果首席設計師喬尼·艾維創立的硬件公司。
而在今年除DeepSeek外最火出圈的AI Agent領域,智譜也是起個大早,趕了晚集。

早在Manus爆火之前的2024年10月,智譜就推出了號稱全球首個設備操控智能體的AutoGLM,但當時智譜對外演示的場景還是點單、發紅包等,相比Manus演示的研報分析、PPT制作等功能,既不剛需,也未能實現破圈效應。
及至Manus出圈后,智譜于3月底跟進推出了AutoGLM升級版——AutoGLM沉思。
但作為AI Agent領域的“后來者”,借助AutoGLM沉思,智譜雖然可以實現媲美Manus的產品效果,但沒有超越和驚艷之處。錯失先發優勢的智譜,并未能引來如Manus一般的產品體驗熱潮。
就像中國知名產品經理之一的傅盛講過的一個觀點,“產品體驗只好20%、30%,沒人會動。產品力得強10倍以上才能擊穿市場。”
靠著提前建立起來的市場認知,短短2個月內,Manus估值就一路水漲船高:先是4月完成由Benchmark領投的7500萬美元融資,估值來到5億美元;后是5月底傳出ARR(年度經常性收入)已接近1億美元,估值飆漲至20億美元,已經逐漸追上了AI六小龍的估值范圍。
同樣錯失AI Agent認知心智建設的OpenAI,則選了一條跟智譜不同的競爭策略,即嘗試將新的Agent直接融入ChatGPT,借助ChatGPT的龐大用戶群,重新奪回用戶注意力。
5月發布完代碼智能體Codex后,OpenAI高管對外直言,下一代基礎模型GPT-5,計劃將Codex、Operator、Deep Research和Memory等功能全部整合在一起。
近期Codex團隊在跟紅杉資本交流時進一步表示,2025注定是Agent元年,而OpenAI的策略則是:未來不再有專門的Agent,ChatGPT將成為唯一通用助手,接入所有接口,并嘗試接管一切。
B
融資環境的變化,無疑成為智譜越來越難跟上OpenAI的一大核心原因。
這家成立于2019年的公司,在ChatGPT發布的2022年底,估值還只有約20億元。到了2023年10月,短短一年多時間,智譜估值就增長了7倍多,飆漲至超120億元,一度成為中國估值最高的大模型創業公司。
彼時,“全面對標OpenAI”的標簽,成了智譜收獲資本寵愛的有力武器。“現在只有智譜AI挑投資機構的份。”2023年上半年時,沒有投進智譜的投資人還這么告訴36氪。
但在日新月異的AI圈,從備受矚目到冷眼相待也只需要一年時間。到了2024年下半年,大模型領域的融資環境就有了變難的趨勢,AI六小龍中已經不時有傳聞稱部分玩家開始放棄預訓練。
恒業資本管理合伙人江一對此深有感受。在他看來,進入2025年,行業對大模型的投資會變得更為謹慎,“類似李開復做出放棄預訓練的決定,在六小龍中幾乎都不同程度存在,就看它們資金能撐到什么時候來對外宣布自己的戰略調整了。”
融資縮水和減少之下,如何讓公司持續生存下去?六小龍幾乎都在2024年盯上了商業化,希望靠自我造血能力,堅持活過更長時間。但事后來看,對應用和商業化的過早投入,反而成為智譜們未能成為下一個“DeepSeek”的原因之一。
彼時,豆包、Kimi、智譜清言等AI助手展開了一場投流大戰,巔峰時期一家的月投流額度就超過億元。但這套投流換取用戶增長的商業邏輯,被DeepSeek的出現而意外打斷。
DeepSeek在20天內狂攬3000萬月活的事實,讓外界開始重新審視大模型廠商所謂的“先發優勢”,并讓部分人意識到用戶數據對模型進步依然有價值,但用戶數據決不會成為模型進步的決定性因素,最終還得靠技術創新。

無論是從AI六小龍縮減后的四小強,還是重燃AI熱情的科技大廠,都達成了一個新共識:想要在大模型領域重獲用戶青睞,唯一的捷徑便是學習DeepSeek,通過技術創新證明自己。2024年掀起的應用和商業化風潮,進入2025年后,在AI四小強身上逐步讓位給技術迭代。
在對外回應張帆離職創業消息中,智譜官方便特意強調,公司“目前將訓練下一代基座模型視為最高優先戰略,專注于持續提升模型性能”。
C
但留給智譜的挑戰遠不止于此。
作為國內首家完成IPO輔導備案的大模型創業公司,智譜無疑比任何人都更需要在商業化上取得新的突破,來保證上市之路的順利。
當前大模型領域的商業化手段,無外乎To C和To B兩大類:To C便是靠收取用戶訂閱費做大收入,例如OpenAI。The Information就曾爆料,隨著付費代理產品和其他新產品的發布,OpenAI預計其收入將在2029年超過1250億美元,其中付費訂閱占比將超過50%。
但這條路顯然不適合眼前的智譜。國內用戶付費意愿低是一方面,智譜清言不足500萬的用戶規模,也決定了其想靠C端實現短期的商業閉環,幾乎是不可能的一件事。
To C不行,便只能To B。服務企業端客戶,目前又分為兩種,一種是直接提供標準化模型方案,如API接口,一種是根據客戶需求做定制化開發,搞項目制。
所有大模型玩家無疑都想走To B服務中的前一條路徑。但現實挑戰在于,愿意接受API服務的中小客戶,客單價太低且需求有限,短時間內難以做大收入規模;能夠給得起價錢的大客戶,又受限于當前大模型能力還不夠通用和泛化,往往需要結合模型做進一步的個性化定制服務。這就難免陷入國內SaaS服務的怪圈,即收入是做大了,但利潤卻沒多多少。

更糟糕的是,隨著DeepSeek的意外爆火,加上阿里通義千問的進一步出圈,智譜原有的企業客戶群,也將不可避免受到新競爭對手的沖擊。
想要進一步穩住客戶,最有力的方式便是保持模型能力的先進性,確保其性能始終處在行業前列。
圍繞大模型玩家的新一輪模型能力大比拼,正在到來。6月中旬,MiniMax終于推出了自己的推理模型。進入7月份,據字母榜獲悉,階躍星辰將對外發布新一代基座模型,月之暗面也有望上線全新多模態模型,DeepSeek R2更是呼之欲出。
如何在一眾模型更新中,拿下外界更多的注意力和關注度,都將考驗著智譜新模型的創新力度。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
